ビジネス
2021/3/31 [WED]
[AD]
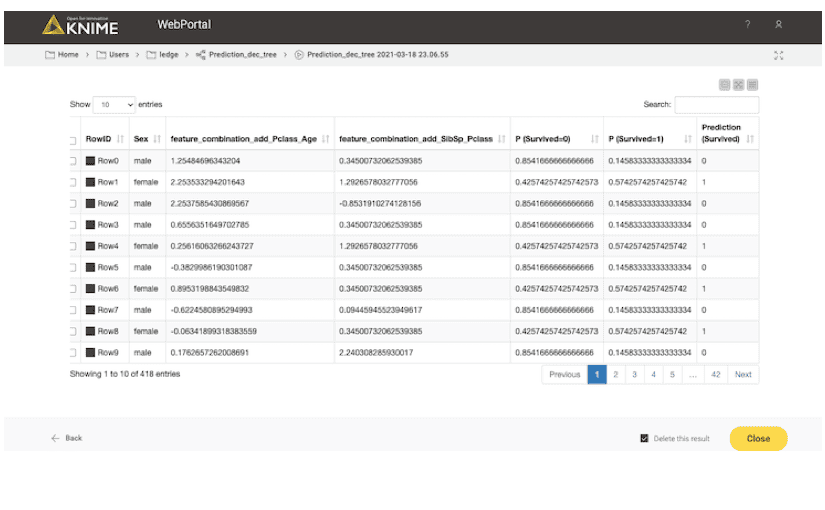
ノーコードでタイタニックの予測モデルを作成してみた「KNIME機械学習自動化パッケージ」レポ
クリップ機能を活用しましょう!
サインインした状態で「いいね」を押すと、マイページの
「いいね履歴」に一覧として保存されていくので、
再度読みたくなった時や、あとでじっくり読みたいときに便利です。
「いいね履歴」に一覧として保存されていくので、
再度読みたくなった時や、あとでじっくり読みたいときに便利です。
クリップ機能を活用しましょう!
サインインした状態で「いいね」を押すと、マイページの
「いいね履歴」に一覧として保存されていくので、
再度読みたくなった時や、あとでじっくり読みたいときに便利です。
「いいね履歴」に一覧として保存されていくので、
再度読みたくなった時や、あとでじっくり読みたいときに便利です。
 Ledge.ai 編集部
Ledge.ai 編集部Ledge.ai編集部です。最新のAI関連技術、テクノロジー、AIのビジネス活用事例などの情報を毎日発信しています。


関連記事
関連する記事が見つかりませんでした


アクセスランキング
ChatGPT以降の労働市場は本当にAIに置き換えられているのか? 500万人分のフリーランスの仕事を分析したリサーチが公開される
イスラエル国防軍、AI標的システム「ラベンダー」を使用してガザのターゲットを特定
Apple 次世代Siriか?音声アシスタントが画面上のコンテキストを「見て」理解できるAI「ReALM」を発表
LoRA(ローラ)とは|今年注目の画像生成AI (Stable Diffusion) のファインチューニングを試してみた
「現状では人間はこの技術を制御しきれない」読売新聞とNTTが生成AIのあり方に関する共同提言「技術と法律の両方で規律する必要性」
福島第一原発1号機の調査に狭小空間点検ドローン「IBIS」が活躍
京都大学、Pythonの基本を解説した無料の教科書「素晴らしすぎる」「非常にわかりやすくて良い」
AI(人工知能)の歴史|時系列で簡単解説
アクセンチュアがオンライン学習企業Udacityを買収 AI人材育成に3年間で10億ドル投資計画
Googleが「Gemini for Google Cloud」を発表 クラウド内での生産性向上を実現
