ラーニング
2020/2/12 [WED]
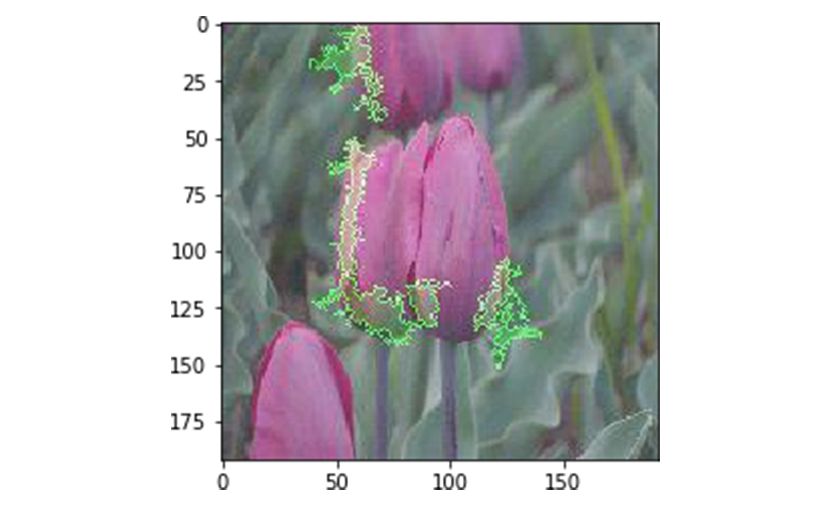
説明可能なAIとは | Googleの「Explainable AI」に触れながら解説
クリップ機能を活用しましょう!
サインインした状態で「いいね」を押すと、マイページの
「いいね履歴」に一覧として保存されていくので、
再度読みたくなった時や、あとでじっくり読みたいときに便利です。
「いいね履歴」に一覧として保存されていくので、
再度読みたくなった時や、あとでじっくり読みたいときに便利です。
クリップ機能を活用しましょう!
サインインした状態で「いいね」を押すと、マイページの
「いいね履歴」に一覧として保存されていくので、
再度読みたくなった時や、あとでじっくり読みたいときに便利です。
「いいね履歴」に一覧として保存されていくので、
再度読みたくなった時や、あとでじっくり読みたいときに便利です。
関連するタグ
 Ledge.ai 編集部
Ledge.ai 編集部Ledge.ai編集部です。最新のAI関連技術、テクノロジー、AIのビジネス活用事例などの情報を毎日発信しています。


関連記事
関連する記事が見つかりませんでした


アクセスランキング
中国の裁判所、偽ウルトラマン画像の生成AI事業者に著作権侵害で20万円の賠償命令ーー AI生成コンテンツの著作権侵害に関する中国初の裁判
ファミリーマートが生成AI導入で関連業務時間を約50%削減と発表 会社全体でAI活用を推進
LoRA(ローラ)とは|今年注目の画像生成AI (Stable Diffusion) のファインチューニングを試してみた
賞金総額は20万ドル以上 クリエータープラットフォームFanvueがAI美人コンテスト「Miss AI」開催
自動作曲ができる音楽生成AI「Udio」パブリックベータ版公開 誰でも無料で月1200曲まで高品質な楽曲を生成できる
経産省が国内AIスパコン整備に725億円の助成 さくらインターネット、GMO、KDDIなど5社
Googleの研究チーム開発の新技術「Infini-attention」無限のテキスト処理を実現ーー長大な文脈を踏まえた濃い内容の応答を可能に
経済産業省 & 総務省、AI事業者向けガイドラインを公表 ― 安全性、透明性、公平性ほか10の指針
Microsoftのトーキングヘッド生成AI「VASA-1」 1枚の静止画と音声データで、その人物があたかも喋っているような動画を生成
Adobe Premiere Proで「Sora」が使える! 年内にもOpenAI、Runwayなどのビデオ生成モデルを統合すると発表
