About
Contact
記事
動画
ソリューション
Sign In
検索
Sign In
記事
動画
ソリューション
About
Contact
Top
>
検索結果
1~12 / 55件
ビジネス
2026
/
6
/
26
[FRI]
Google、Gemini 3.5 Flashに画面操作機能「Computer Use」を統合 ブラウザ・モバイル・デスクトップ操作に対応
Google
AIエージェント
マルチモーダルAI
ビジネス
2026
/
5
/
20
[WED]
Google I/O 2026開催——最新基盤モデルGemini 3.5 Flash発表 24時間動く個人AIエージェント「Gemini Spark」とマルチモーダルモデルGemini Omniなども公開
Google
基盤モデル
AIエージェント
マルチモーダルAI
ビジネス
2026
/
4
/
10
[FRI]
Meta、Superintelligence Labs初のAIモデル「Muse Spark」発表 Meta AIアプリとWebで提供開始
Meta
基盤モデル
マルチモーダルAI
ビジネス
2026
/
1
/
14
[WED]
リコー、「文書×AI」を現場仕様に──Qwen2.5-VL-32B基盤、視覚データ60万枚でチューニング
マルチモーダルAI
基盤モデル
国内企業事例
ビジネス
2025
/
11
/
15
[SAT]
AIの"ゴッド・マザー" Fei-Fei LiのWorld Labs、マルチモーダル世界モデル「Marble」を一般公開──テキスト・画像・動画から“永続3Dワールド”生成
マルチモーダルAI
基盤モデル
学術&研究
2025
/
10
/
7
[TUE]
Google ResearchとDeepMind、「StreetViewAI」を発表──視覚障害者がAIと対話しながらストリートビューを“歩く”
Google
マルチモーダルAI
エンタメ&アート
2025
/
8
/
2
[SAT]
Runway、動画編集を一新するAIモデル「Aleph」発表──物体除去から新アングル生成まで
マルチモーダルAI
エンタメ&アート
2025
/
4
/
25
[FRI]
Adobe、生成AI基盤「Firefly」を刷新——画像・動画・音声・ベクターを統合し、OpenAI・Googleモデルも選択可能に
マルチモーダルAI
ビジネス
2025
/
4
/
17
[THU]
OpenAI、推論特化型の新モデル「o3」「o4-mini」を同時リリース——画像を“思考”に組み込み、全ツールを自律的に呼び出す
AIエージェント
OpenAI
マルチモーダルAI
基盤モデル
ビジネス
2025
/
4
/
7
[MON]
Meta、「Llama 4」発表 オープンウェイトで進化するネイティブマルチモーダルAIの可能性
Meta
マルチモーダルAI
基盤モデル
学術&研究
2025
/
4
/
3
[THU]
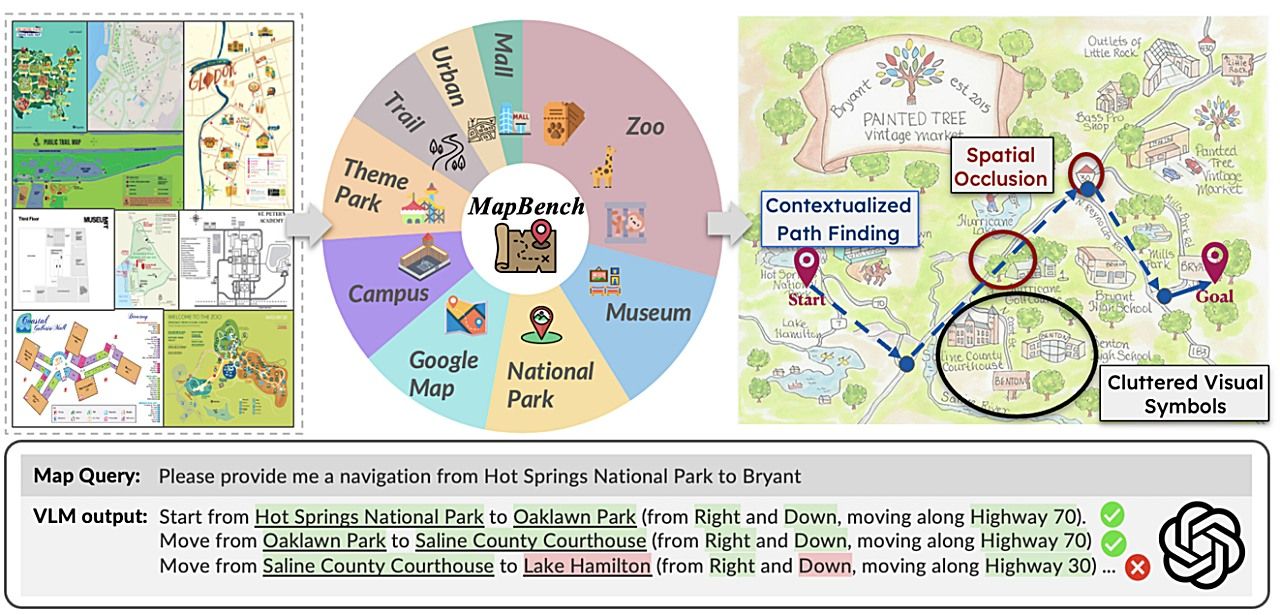
地図を読み取り、目的地までのルートを言語で説明できるAIは誕生するか──新ベンチマークMapBenchが明らかにした大規模視覚言語モデル(LVLM)の限界
マルチモーダルAI
ビジネス
2025
/
4
/
3
[THU]
Apple Vision Proに「Apple Intelligence」機能を統合──visionOS 2.4で提供開始。まずは米国圏・英語ユーザーから
Apple
AIエージェント
マルチモーダルAI
ビジネス
2026
/
6
/
26
[FRI]
Google、Gemini 3.5 Flashに画面操作機能「Computer Use」を統合 ブラウザ・モバイル・デスクトップ操作に対応
Google
AIエージェント
マルチモーダルAI
Google
AIエージェント
マルチモーダルAI
ビジネス
2026
/
5
/
20
[WED]
Google I/O 2026開催——最新基盤モデルGemini 3.5 Flash発表 24時間動く個人AIエージェント「Gemini Spark」とマルチモーダルモデルGemini Omniなども公開
Google
基盤モデル
AIエージェント
マルチモーダルAI
Google
基盤モデル
AIエージェント
マルチモーダルAI
ビジネス
2026
/
4
/
10
[FRI]
Meta、Superintelligence Labs初のAIモデル「Muse Spark」発表 Meta AIアプリとWebで提供開始
Meta
基盤モデル
マルチモーダルAI
Meta
基盤モデル
マルチモーダルAI
ビジネス
2026
/
1
/
14
[WED]
リコー、「文書×AI」を現場仕様に──Qwen2.5-VL-32B基盤、視覚データ60万枚でチューニング
マルチモーダルAI
基盤モデル
国内企業事例
マルチモーダルAI
基盤モデル
国内企業事例
ビジネス
2025
/
11
/
15
[SAT]
AIの"ゴッド・マザー" Fei-Fei LiのWorld Labs、マルチモーダル世界モデル「Marble」を一般公開──テキスト・画像・動画から“永続3Dワールド”生成
マルチモーダルAI
基盤モデル
マルチモーダルAI
基盤モデル
学術&研究
2025
/
10
/
7
[TUE]
Google ResearchとDeepMind、「StreetViewAI」を発表──視覚障害者がAIと対話しながらストリートビューを“歩く”
Google
マルチモーダルAI
Google
マルチモーダルAI
エンタメ&アート
2025
/
8
/
2
[SAT]
Runway、動画編集を一新するAIモデル「Aleph」発表──物体除去から新アングル生成まで
マルチモーダルAI
マルチモーダルAI
エンタメ&アート
2025
/
4
/
25
[FRI]
Adobe、生成AI基盤「Firefly」を刷新——画像・動画・音声・ベクターを統合し、OpenAI・Googleモデルも選択可能に
マルチモーダルAI
マルチモーダルAI
ビジネス
2025
/
4
/
17
[THU]
OpenAI、推論特化型の新モデル「o3」「o4-mini」を同時リリース——画像を“思考”に組み込み、全ツールを自律的に呼び出す
AIエージェント
OpenAI
マルチモーダルAI
基盤モデル
AIエージェント
OpenAI
マルチモーダルAI
基盤モデル
ビジネス
2025
/
4
/
7
[MON]
Meta、「Llama 4」発表 オープンウェイトで進化するネイティブマルチモーダルAIの可能性
Meta
マルチモーダルAI
基盤モデル
Meta
マルチモーダルAI
基盤モデル
学術&研究
2025
/
4
/
3
[THU]
地図を読み取り、目的地までのルートを言語で説明できるAIは誕生するか──新ベンチマークMapBenchが明らかにした大規模視覚言語モデル(LVLM)の限界
マルチモーダルAI
マルチモーダルAI
ビジネス
2025
/
4
/
3
[THU]
Apple Vision Proに「Apple Intelligence」機能を統合──visionOS 2.4で提供開始。まずは米国圏・英語ユーザーから
Apple
AIエージェント
マルチモーダルAI
Apple
AIエージェント
マルチモーダルAI
<
1
2
3
4
5
>
アクセスランキング
7日間
30日間
東京都、都庁舎にAI自動分別リサイクルボックス設置 リチウムイオン電池内蔵製品を回収
Claude CodeでAIエージェントをどう指示するか AnthropicがCLAUDE.md・スキル・サブエージェントなど7つの方法を解説
OpenAI、GPT-5.6を発表 最上位「Sol」、低価格「Terra」、高速「Luna」の3モデルを限定プレビュー
4
コードエディタ開発のZed、AIとの開発履歴を会話とひも付けて記録する「DeltaDB」発表
5
Google、データセンターの水使用量を上回る「水の補充」へ 2030年までに年間190億ガロン超を見込む
6
Claude Codeは誰が何に使い、成果はどこで分かれるのか――Anthropicが利用データ40万件を分析
7
GoogleからAIの大物の流出が相次ぐ ノーベル賞研究者がAnthropic、Gemini共同リードはOpenAIへ
8
AGIの次に来る「超知能」をどう測るか Google DeepMind論文が示す、AIベンチマークと予測研究
9
AI価格設定ソフトでガソリン価格をつり上げたとして集団訴訟 BP、Walmart、7-Elevenなどが対象に
10
プリファード、フルスクラッチ開発の国産生成AI基盤モデル「PLaMo 3.0 Prime」を正式提供 Reasoning/Non-reasoningモデルをAPI・オンプレで展開
人気のタグ
AIエージェント
モビリティ×AI
半導体
基盤モデル
ロボティクス
マルチモーダルAI
EXPO2025
サイバーセキュリティ
近未来
日本政府
FOLLOW US
各種SNSでも最新情報をお届けしております
人気のタグ
AIエージェント
モビリティ×AI
半導体
基盤モデル
ロボティクス
マルチモーダルAI
EXPO2025
サイバーセキュリティ
近未来
日本政府