ラーニング
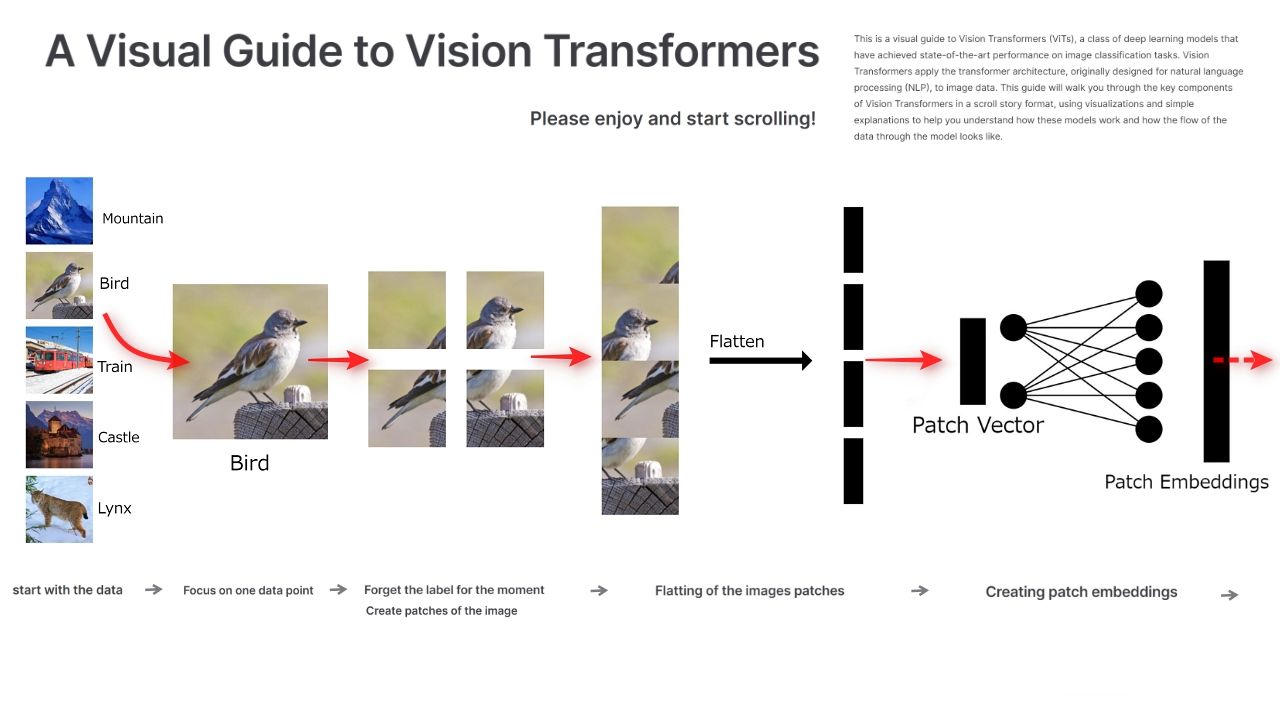
GWに徹底理解!「Vision Transformer」 LLMの基幹技術 Transformer を画像分類に応用した大注目技術が分かりやすいビジュアルガイドに
Googleが開発したトランスフォーマー技術は、自然言語処理から画像分類へとその応用範囲を広げ、新たなAIモデル「Vision Transformer(ViT)」が登場した。このモデルは、画像を小さなパッチに分割し、それぞれのパッチを独立したデータポイントとして処理することで、画像全体の文脈を捉える能力を持っているという。 もともとテキストデータ向けに開発されたトランスフォーマーは、その強力な自己注意機構(Self-Attention Mechanism)により、文中の各単語がどのように相互作用するかを学習する。このメカニズムを画像データに応用したことで、ViTは画像の各部分がどのように関連しているかを効率的に解析し、従来の畳み込みニューラルネットワークモデルと比較して高精度な画像分類を実現しているとのこと。 ソフトウェアエンジニアであるデニス・タープ氏は、この複雑なモデルを「[A Visual Guide to Vision Transformers]{target=“_blank”}」というビジュアルガイドでわかりやすく解説している。 このガイドでは、ViTの構造とデータの流れをステップバイステップで説明し、専門家でない読者にも理解しやすい内容となっている。特に、画像をパッチに分割し、それぞれのパッチがどのようにネットワーク内で処理されるかを視覚的に示している点が特徴的だ。 「Please enjoy and start scrolling!(スクロールしてお楽しみください)」と書かれているとおり、縦スクロールで次々と解説が進む作りになっている。[ガイドはこちら]{target=“_blank”}から。 :::box [関連記事:GWに徹底理解!GPTの仕組みをめちゃくちゃ分かりやすく解説する無料動画公開] ::: :::box [関連記事:Googleの研究チーム開発の新技術「Infini-attention」無限のテキスト処理を実現ーー長大な文脈を踏まえた濃い内容の応答を可能に] ::: :::box [関連記事:ChatGPT(チャットGPT)とは|今からでも遅くない、使い方の基本と知っておくべきこと] :::

AIエージェントとは|マニアックなプロンプトエンジニアリングはいらない 注目の生成AI活用トレンド

Google の無料教材公開「Beyond the Prompt」「Prompting guide 101」生成AIの効果的な活用法やヒントを紹介
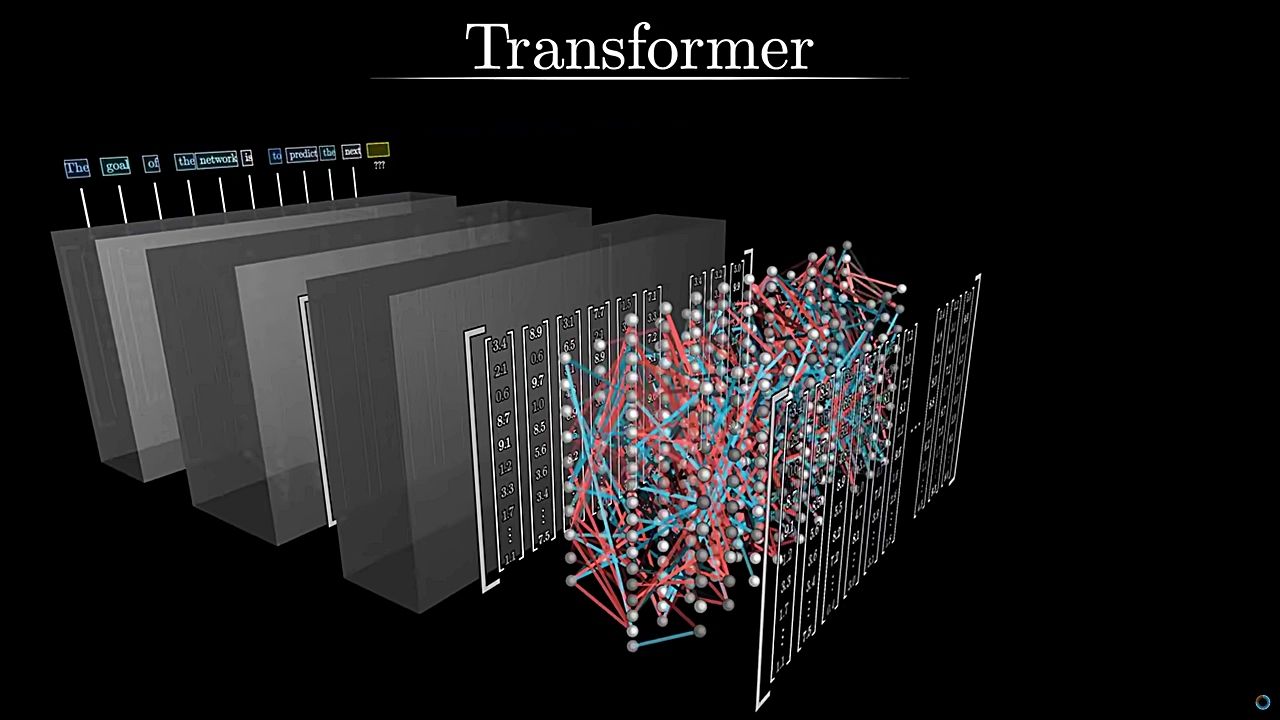
GWに徹底理解!GPTの仕組みをめちゃくちゃ分かりやすく解説する無料動画公開

NVIDIA、生成AI分野の技術者向けにプロフェッショナル認定制度を新設
Anthropic、チャットAI「Claude 3」向け公式プロンプト集を公開
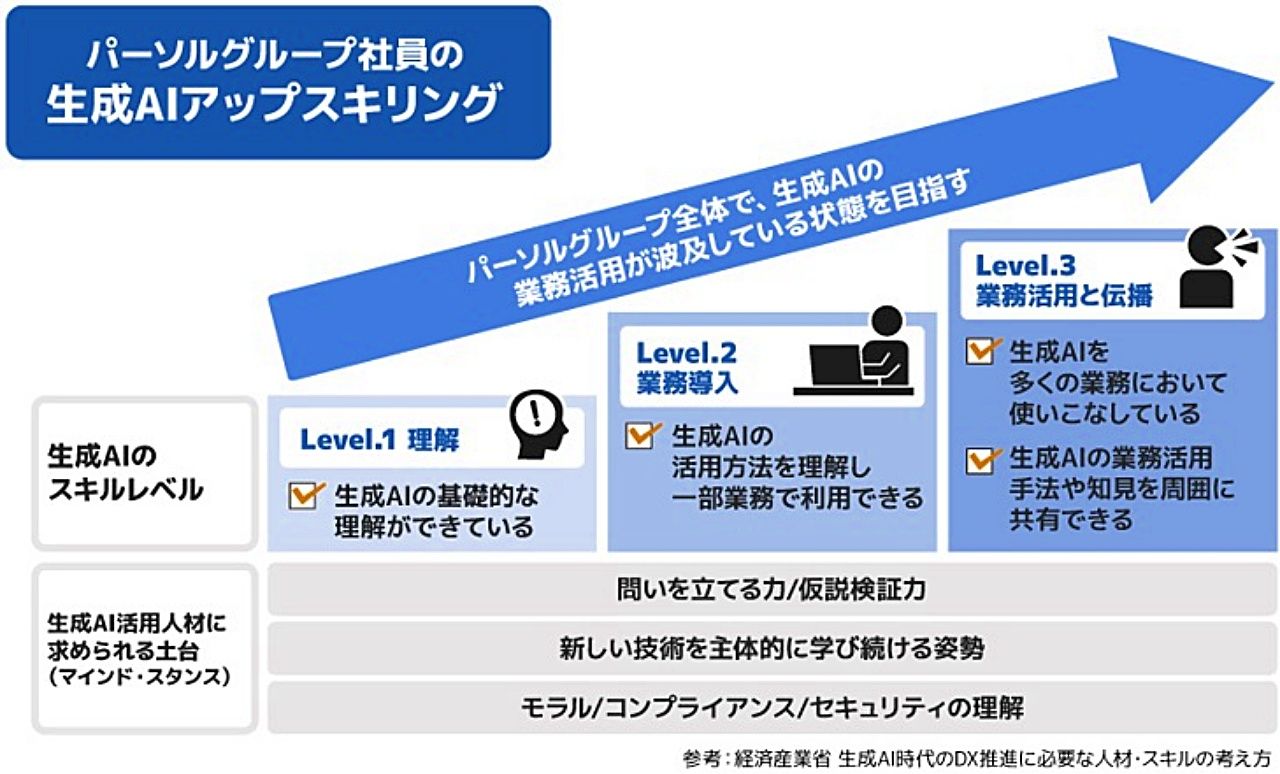
パーソルホールディングス、生成AI研修で社員スキルアップを加速
JDLAが「生成AIの利用ガイドライン(画像編)」を公開

日本最大級のDX推進コンテスト『日本DX大賞2024』応募開始

LoRA(ローラ)とは|今年注目の画像生成AI (Stable Diffusion) のファインチューニングを試してみた

Webアプリケーションの巡回ツールを開発せよ|MBSD Cybersecurity Challenges 2023

大学入試の記述式対策もAI活用 駿台、AI学習教材「スルメ」で特許を取得

GPT Store(GPTストア)とは|GPTを公開して収益化する方法


